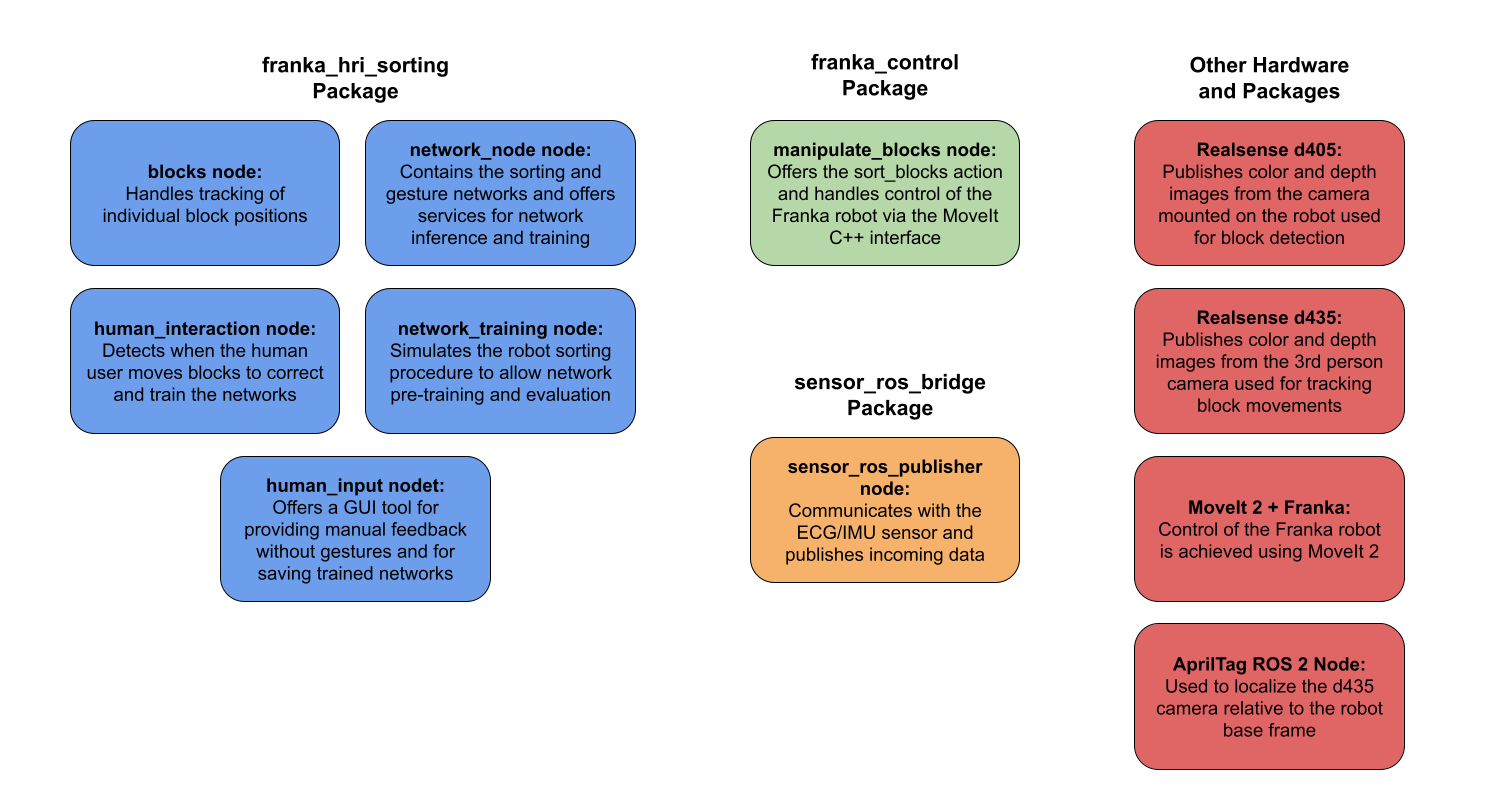
Robot Arm Sorting with Online Learning via Human Interaction
Video Demo
Overview
In this project, I developed a novel interactive learning system that enables a robot arm to learn sorting behaviors through natural human interaction. The system combines computer vision, online learning, and natural human interaction to create a robot that can learn and refine sorting criteria throughout operation.
At its core, the system utilizes a Franka Panda robotic arm equipped with a depth camera for precise block detection and manipulation. A separate camera monitors the workspace for human interventions, enabling natural corrections through physical demonstrations. Finally, a combined ECG/IMU sensor worm by the operator enables corrections to the robot’s behavior via gesture control.
The system architecture integrates three neural networks:
- Complex sorting network for four-category block classification
- Binary gesture network for yes/no feedback validation
- Complex gesture network for direct category corrections
This multi-network approach enables fluid human-robot interaction, where users can either confirm the robot’s decisions through gestures or physically move blocks to demonstrate correct sorting. The system continuously learns from these interactions, improving its sorting accuracy over time. The project demonstrates how combining traditional robotic control with adaptive learning and natural interaction modes can create systems that efficiently learn from and collaborate with human operators.
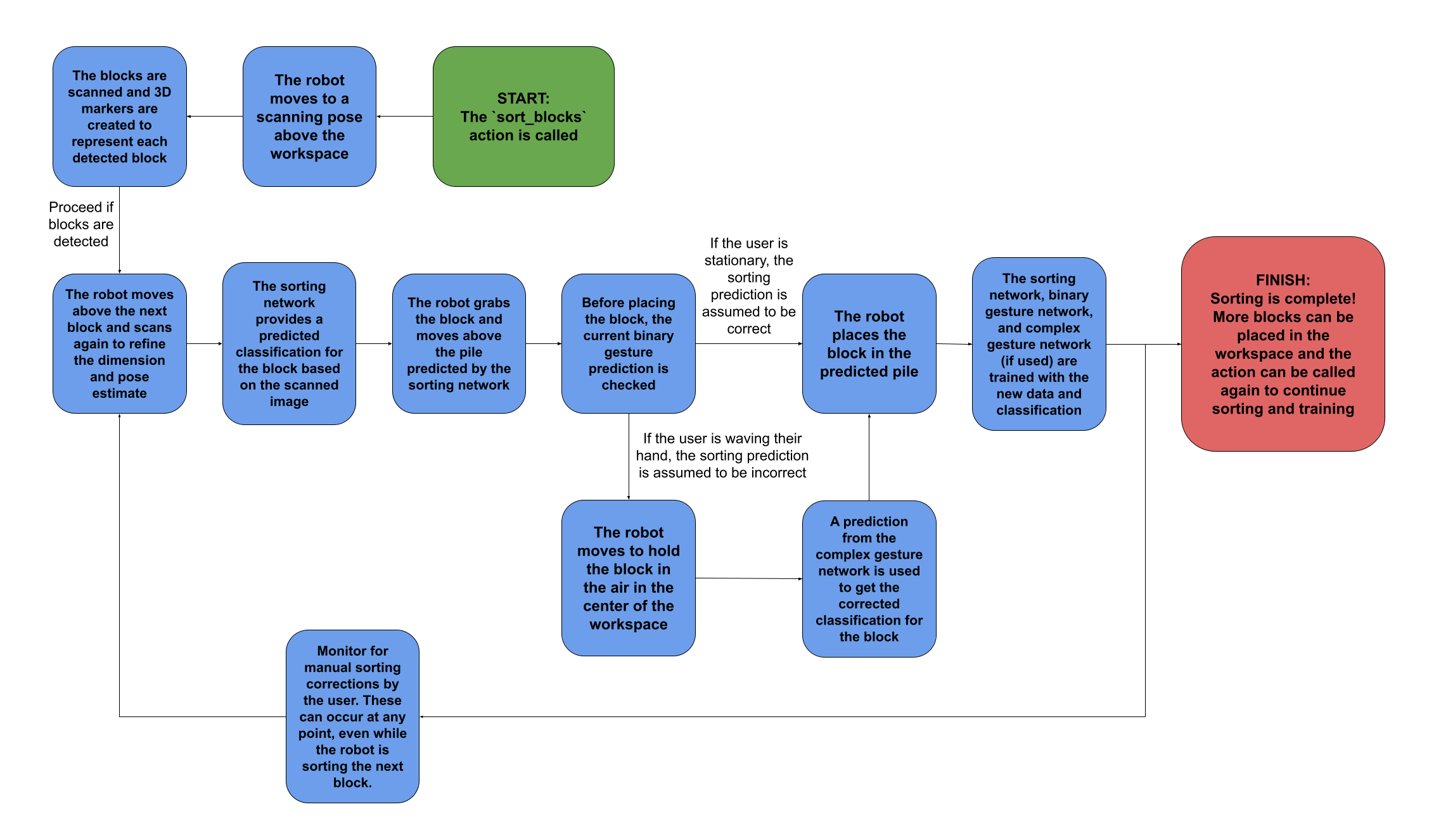
Sorting Process Overview
The full sorting procedure is summarized in the block diagram below.
- System Architecture
- Uses ROS 2 framework with both C++ (robot control) and Python (ML/vision) nodes
- Integrates MoveIt for motion planning with the Franka Panda robot arm
- Uses depth cameras for visual perception
- Implements custom neural networks for both object sorting and gesture recognition
- Main Control Flow
- A sorting demonstration can optionally be given by the user to help pre-train the sorting network
- The sorting starts when the ‘sort_blocks’ action is called
- The robot moves to a scanning pose above the workspace
- A RealSense depth camera scans for blocks and creates 3D markers for detected objects
- Robot moves to scan the first detected block
- Sorting network predicts classification
- Robot grabs block and moves to wait position
- Gesture recognition checks for human agreement/disagreement
- Block is placed in appropriate pile based on final decision
- The process repeats until all blocks are sorted
- Interactive Learning
- Three neural networks work in parallel
- Sorting network: Classifies blocks based on visual features (4 categories)
- Binary Gesture network: Interprets human gestures for yes/no feedback
- Complex Gesture network: Interprets human gestures for sorting classifications (4 categories)
- Networks are continuously trained during operation
- Human-Robot Interaction
- Allows gesture-based corrections of sorting decisions
- Monitors for physical intervention (hand detection)
- Supports continuous learning from human feedback
The system combines autonomous operation with human oversight, enabling efficient sorting with continuous improvement through human feedback.
Below is a summary of the nodes used for this task:
Neural Network for Block Sorting
The system uses a sorting network built in PyTorch, designed for multi-category block classification. The network processes RGB images from the RealSense camera mounted on the robot’s end-effector and outputs classification decisions into four distinct categories.
Network Architecture The architecture consists of three convolutional layers with batch normalization and max pooling for feature extraction, followed by three fully connected layers. Key features include:
- Input: 128x128 RGB images from RealSense camera
- Progressive feature extraction through three conv-pool stages
- Extensive regularization with batch normalization and dropout (0.5, 0.3)
- Four-category output using softmax activation
- Learning rate decay (γ=0.98) for stable online learning
- Cross-entropy loss with Adam optimizer
Input: 128x128x3 RGB images
Convolutional Layers
- Conv2D(16 filters, 3x3) -> BN -> ReLU -> MaxPool(2x2) -> 64x64x16
- Conv2D(32 filters, 3x3) -> BN -> ReLU -> MaxPool(2x2) -> 32x32x32
- Conv2D(64 filters, 3x3) -> BN -> ReLU -> MaxPool(2x2) -> 16x16x64
Output Layers
- Flatten(16,384) -> Dense(256) -> Dropout(0.5) -> Dense(64) -> Dropout(0.3) -> Dense(4)
- Softmax activation
- Learning rate: 0.0001, decay: 0.98
Online Learning System
- Maintains balanced class buffers (25 samples per category) which are filled in as the robot see and sorts more blocks
- State management for correction handling:
- Caches network and buffer states before training
- Enables rollback for incorrect predictions
- Tracks confusion matrices and confidence metrics
Pretraining by Demonstration
The system provides a demonstration-based pretraining phase to establish initial sorting knowledge:
- Initial Workspace Setup:
- Blocks are arranged in predefined quadrants of the workspace
- Spatial locations define initial category labels:
- Back left: Category 0
- Front left: Category 1
- Back right: Category 2
- Front right: Category 3
- Automated Learning Process:
- Robot performs overhead scan to detect all blocks
- For each detected block:
- Assigns category based on block’s quadrant location
- Creates training examples and updates category buffers
- Trains the sorting network as each image is added to the buffer
The pretraining phase provides the network with an initial understanding of visual features associated with each category, creating a higher baseline for further learning through interaction.
Gesture Feedback Sensor
Human-robot interactions in the project were facilitated by a wearable sensor created by Yayun Du of the Simpson Querrey Biomedical Research Center at Northwestern. This sensor features both a single channel ECG sensor and a 6-axis IMU to provide robust information about the behavior of the user. The sensor can be placed in a variety of locations on the body to sense different thing, from hand gestures to eye movements. For this application, it made the most sense to locate it on the wrist, where it would easily be able to return data about hand gestures, which could be used for guiding the robot in the sorting task.
Below are images showing the sensor itself and the positioning of the sensor on the arm. Once in the right position, the sensor is secured with adhesive pads to hold it in place.


Two different types of gestures were used for this project. First, a yes/no binary gesture classification was used to confirm or correct a prediction made by the robot. I decided to make the “yes” gesture simply staying stationary, while the “no” gesture was making a cutting motion with your hand. This way, if the robot is sorting correctly, the user can simply stay in place and do nothing and the robot will proceed with sorting. The gif below shows examples of the two gestures.

For getting sorting feedback, a four way gesture network (the “complex” gesture network) was used. The network itself is described in more detail below. The four gestures used are shown in the GIF below, and were each selected to take advantage of the specific sensing modalities of the sensor. These gestures each have very different ECG and IMU signals, due to the clenching and unclenching of the fist and the different directions of motion. This made classification very accurate and robust after training.

The sensor communicates with the computer via Bluetooth. I created a ROS 2 node to interface between the sensor and the ROS systems. The node publishes the sensors data to topics so it can be processed by the network_node for use in gesture predictions.
Neural Networks for Gesture Control
The system implements two complementary gesture networks for human feedback - a binary network for yes/no feedback and a complex network for direct category selection:
Gesture Classification Data Processing
- Processes 4-channel time-series data from IMU sensors
- Sequence normalization using running maximum values
- Dynamic sequence padding/truncation to maintain 20-step sequences
- Feature concatenation from multiple sensor modalities for comprehensive gesture capture
Gesture Data Normalization
- Gesture data is normalized using maximum values collected using the
collect_norm_valuesservice - This service collects data over a short period, then extracts and saves maximum values for normalization
- The user should clench their first and wave their arm around vigorously
- This normalization significantly increased the accuracy of gesture predictions
Binary Gesture Network (Yes/No)
- 1D convolutional architecture
- Two convolutional layers with batch normalization and max pooling
- Three fully connected layers with dropout for robust classification
- Maintains 100-sample buffer for stable training
- Binary classification with BCE loss
- Higher initial learning rate (0.0005) for quick adaptation
Input: 4 channels x 1000 timepoints (reshaped from 20x50)
Convolutional Layers
- Conv1D(32 filters, k=5, s=2) -> BN -> ReLU -> MaxPool -> 250 timepoints
- Conv1D(64 filters, k=5, s=2) -> BN -> ReLU -> MaxPool -> 62 timepoints
Output Layers
- Flatten(3,968) -> Dense(128) -> Dropout(0.5) -> Dense(32) -> Dropout(0.3) -> Dense(1)
- Sigmoid activation
- Learning rate: 0.0005, decay: 0.98
Complex Gesture Network (Multi-Category)
- Larger convolutional layers (64 and 128 channels)
- Expanded fully connected layers for multi-class discrimination
- Four-category classification for direct sorting decisions
- Slower learning rate (0.00025) with gentler decay (γ=0.99)
- Buffer management for multi-class balance
Input: 4 channels x 1000 timepoints (reshaped from 20x50)
Convolutional Layers
- Conv1D(64 filters, k=5, s=2) -> BN -> ReLU -> MaxPool -> 250 timepoints
- Conv1D(128 filters, k=5, s=2) -> BN -> ReLU -> MaxPool -> 62 timepoints
Output Layers
- Flatten(7,936) -> Dense(256) -> Dropout(0.5) -> Dense(64) -> Dropout(0.3) -> Dense(4)
- Softmax activation
- Learning rate: 0.00025, decay: 0.99
Network Integration Both networks operate in parallel during deployment:
- Binary network provides quick validation of sorting decisions
- Complex network enables direct category corrections when needed
- Asynchronous service-based prediction and training for both networks
- Performance logging and analysis:
- Tracks accuracy and confidence metrics
- Maintains confusion matrices
- Records correction statistics
- Data collection for continuous improvement:
- Saves training samples with timestamps
- Records sequence data for offline analysis
- Tracks model evolution through corrections
Franka Panda Control with MoveIt
The system integrates with MoveIt through the MoveGroupInterface and PlanningSceneInterface, which provide core functionality for motion planning and collision avoidance. Key custom functions were developed to handle common operations:
Core Movement Functions:
move_to_pose(): Handles Cartesian space movement with configurable planning time and velocity/acceleration scalingmove_to_joints(): Provides direct joint space control for predefined configurations like the home positioncreate_collision_box()andremove_collision_box(): Manage collision objects for blocks and workspace boundariesscan_block(): Executes a two-stage scanning motion sequence, first moving to a hover position above the target block, then to a precise scanning pose. This function coordinates with the vision system to update marker information and block dimensions.grab_block(): Implements a multi-stage grasping operation that approaches blocks through hover and grasp poses. This function manages gripper control and updates collision tracking to reflect attached objects.place_in_stack(): Handles the complete block placement sequence, managing stack heights, creating new stacks when needed, and coordinating collision object updates. The function ensures smooth transitions and proper spacing between blocks.place_block(): Executes the final placement operation with precise position control and gripper release sequencing. This function includes retreat motions and updates marker positions to maintain accurate workspace representation.
The system uses MoveIt’s planning scene to maintain a real-time representation of the workspace:
- Tables and workspace boundaries are defined as permanent collision objects
- Dynamic collision objects are created for each block as it’s detected
- Objects are attached/detached from the gripper during manipulation
- Stack positions are tracked and updated to manage collision avoidance during placement
All motion planning is then executed through MoveIt’s pipeline using the MoveIt C++ API.
Block Detection
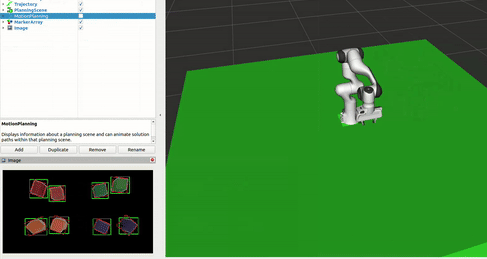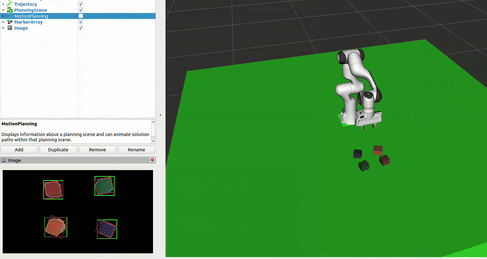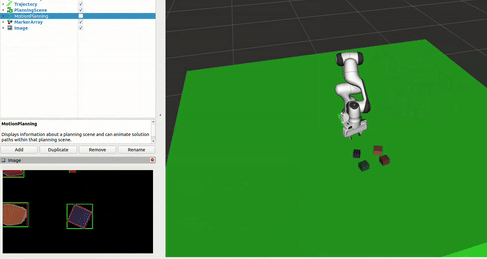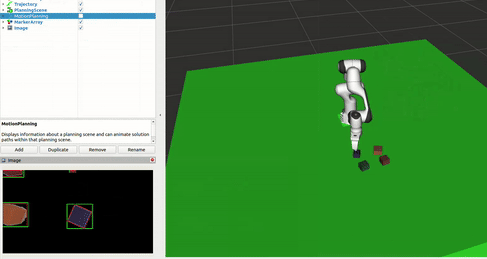
The block detection system employed computer vision techniques to accurately detect blocks, their dimensions, positions, and orientations. Key aspects included:
- Camera Setup:
- Utilized both color and depth information from a d405 RealSense camera mounted on the robot gripper. This camera is optimized for close range and high accuracy.
- To scan, the robot hand hovers above the workspace with the gripper and camera pointing straight down, where it can see the blocks.
- Depth data provided 3D positioning of the table in 3d space, while color data helps with block detection and segmentation.
- Depth Segmentation:
- Implemented a custom depth segmentation algorithm to isolate the table surface.
- Used Gaussian blur and Canny edge detection on the depth image.
- Applied Hough line transform to identify table edges.
- Created a mask to separate the table surface from the background.
- Color-based Block Segmentation:
- Applied color thresholding to isolate potential block regions.
- Used morphological operations (opening and closing) to reduce noise and refine block shapes.
- Contour Analysis:
- Detected contours in the segmented image using cv2.findContours().
- Analyzed contour properties (area, aspect ratio) to filter out non-block objects.
- Used cv2.minAreaRect() to find the oriented bounding box of each block.
- 3D Pose Estimation:
- Calculated block orientation using the angle of the minimum area rectangle.
- Estimated block dimensions using the contour’s bounding rectangle and depth information.
- Depth data was used to estimate the height of the block.
Interaction and Block Correction
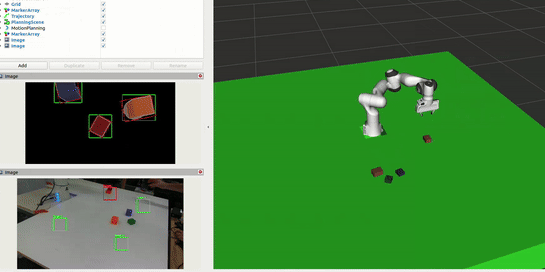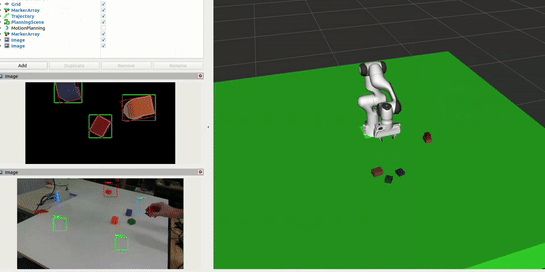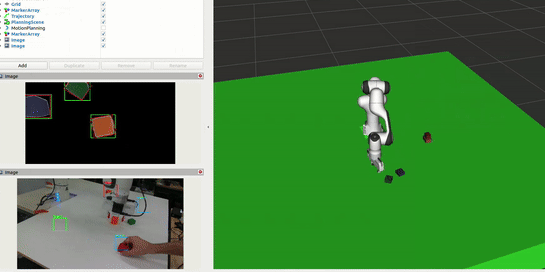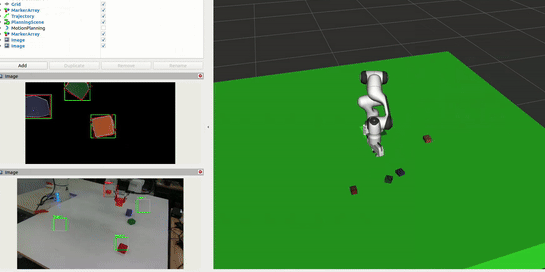
The system continuously monitors the workspace to enable natural human interaction in the sorting process. This allows users to physically adjust block placements while the system learns from these corrections:
Vision-Based Monitoring:
- Uses RealSense D435i camera for monitoring workspace state
- Continuous hand detection using MediaPipe hands detector
- Monitors predefined regions around:
- Current block position
- All potential stack positions
- Real-time depth change analysis for reliable interaction detection
Interaction Detection Pipeline:
- Pre-Interaction State
- Captures baseline color and depth images when hands enter workspace
- Tracks specific monitoring regions around current and potential block positions
- Uses depth thresholding to detect significant changes
- Movement Detection
- Analyzes depth changes in monitored regions after hands leave
- Identifies block removal from original position
- Detects block addition in new stack locations
- Uses configurable thresholds for robust change detection
- State Updates
- Updates internal block tracking based on detected movements
- Triggers network retraining based on human corrections
- Maintains consistency between physical state and system’s internal representation
- Updates all three networks when corrections occur using the correction services described above
Network Corrections
The network_node offers services to correct incorrect training each of the networks. These services reverse the incorrect training and retrain the network with the correct classification. This enables continuous learning from human feedback via physical interventions after the robot has already trained and updated the networks:
- State Caching:
- Each prediction caches a complete
NetworkStateincluding:- Model parameters (weights and biases)
- Optimizer state (momentum and adaptive learning rates)
- Learning rate scheduler configuration
- Training buffer contents for each category
- Original prediction and confidence values
- Each prediction caches a complete
- Correction Process:
- System retrieves last training sample including cached state
- Removes incorrect example from its original category buffer
- Adds sample to correct category buffer with new label
- Reconstructs balanced training batch from all category buffers
- Retrains network using corrected and balanced data
Camera Localization
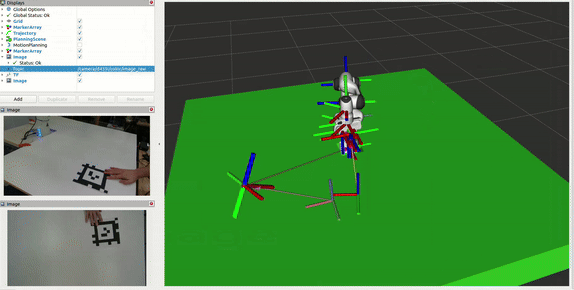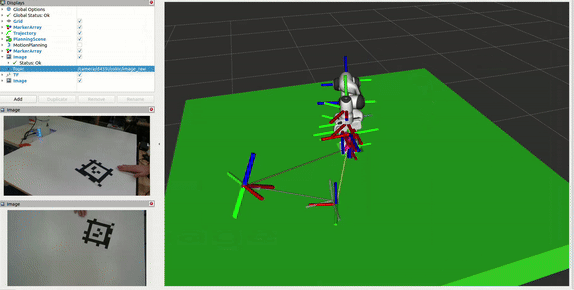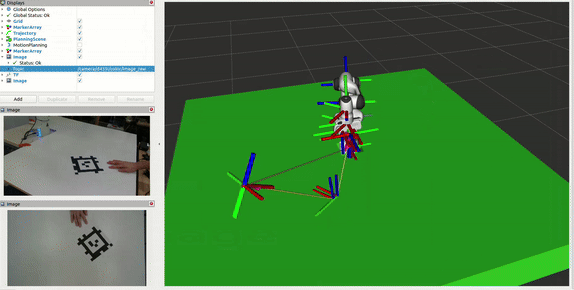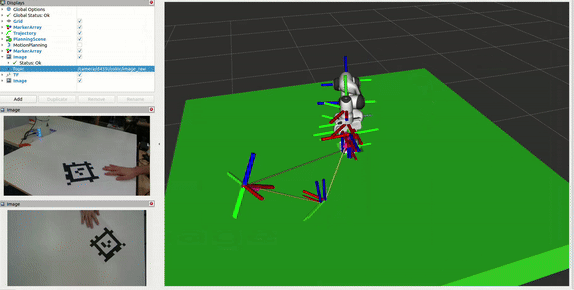
The system uses AprilTag-based localization to accurately determine the D435 monitoring camera’s position in the workspace:
- Multi-Stage Transform:
- Tracks AprilTag in both D405 (mounted on arm) and D435 frames
- Uses D405 tag detection to establish world->tag transform
- D435 provides tag->camera transform
-
Combines transforms to get precise world->D435 camera transform
- Calibration Saving and Loading:
- Saves calibration to CSV file for persistent storage
- Loads previous calibration on startup if available
- Provides service interface for recalibration
-
Broadcasts world->d435_link transform continuously through TF system
- Importance for Block Monitoring:
- Accurate camera position enables precise workspace monitoring
- Transforms block positions from world frame to camera frame
- Allows accurate region monitoring for block movements
Network Training and Evaluation
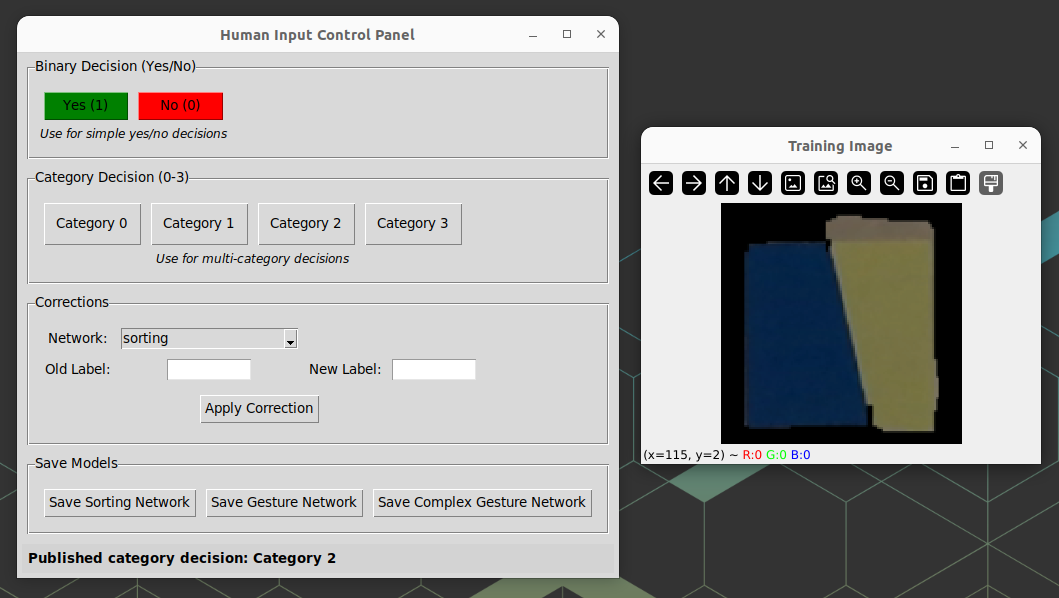
The network_training node provides functionality for testing and training the networks without using the robot system:
- Training Modes:
- Sorting Only: Block classification only
- Gestures Only: Training gesture networks only
- Combined: Simultaneous training of two networks
- Supports both binary and complex gesture networks
- Visual Interface:
- Real-time display of training images
- Visual feedback of network predictions
- Confidence metrics for each classification
- Wait states for human feedback collection
- Training Process:
- System loads and displays random training image or waits for gesture
- Networks make initial predictions
- System displays predictions with confidence scores
- Human provides correct labels or confirms predictions
- Networks update based on feedback
This node acts as both a training and evaluation tool, enabling training sessions to improve network performance and evaluation of trained networks.
Online Training Results
The gesture networks were pretrained.
Binary Gestures:
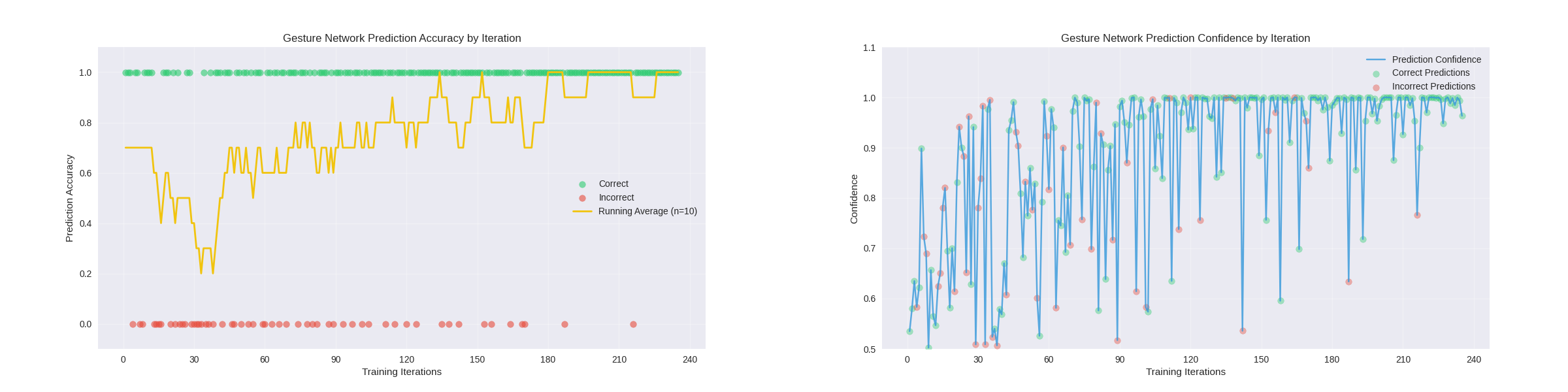
Complex Gestures:
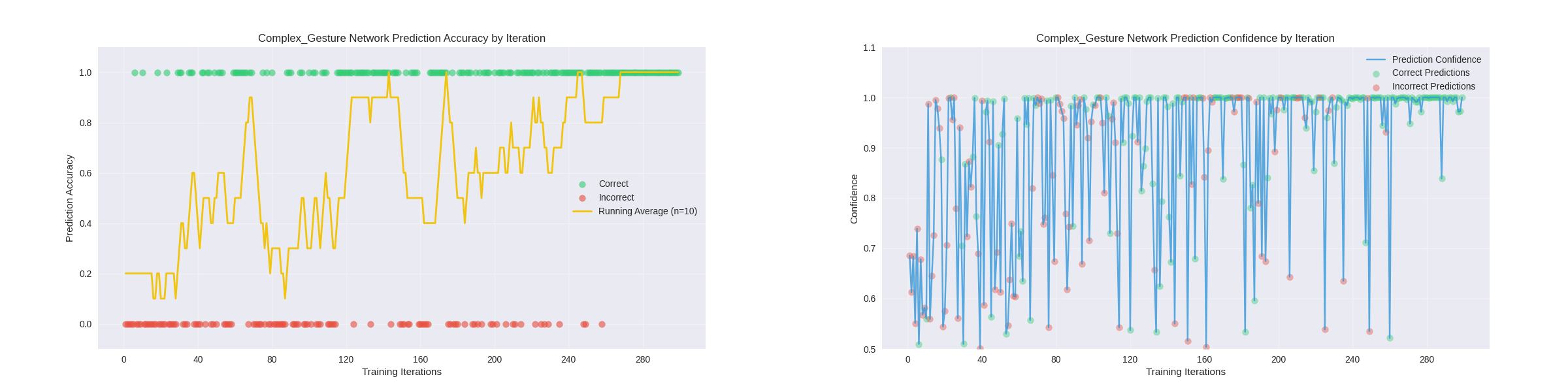
Below is the online training of the solid color blocks. The first graph represents the outcomes of the video at the top of this post. The second set of graphs represent an extended training session using the network_training node.
Demo:
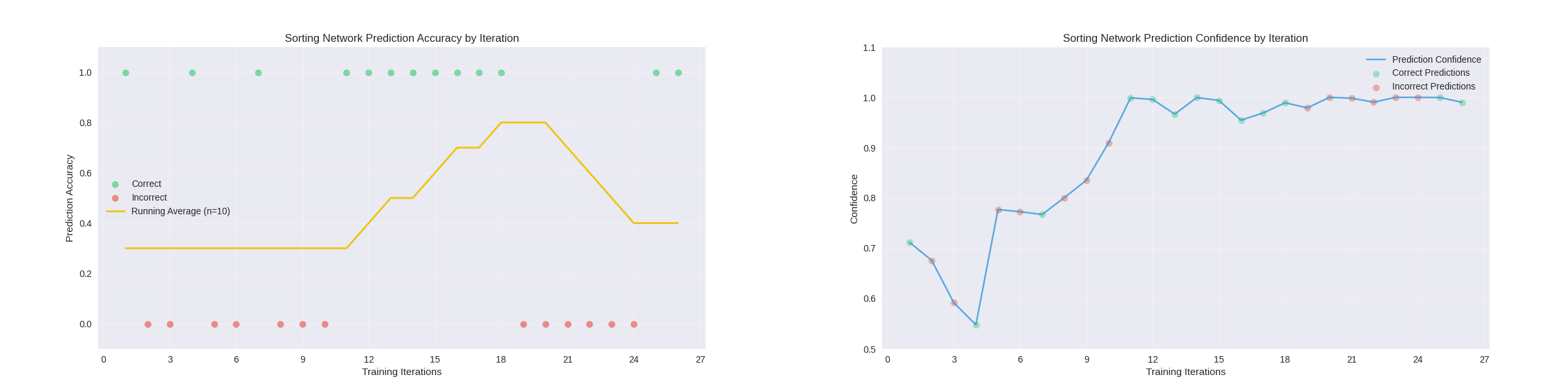
Extended Training:
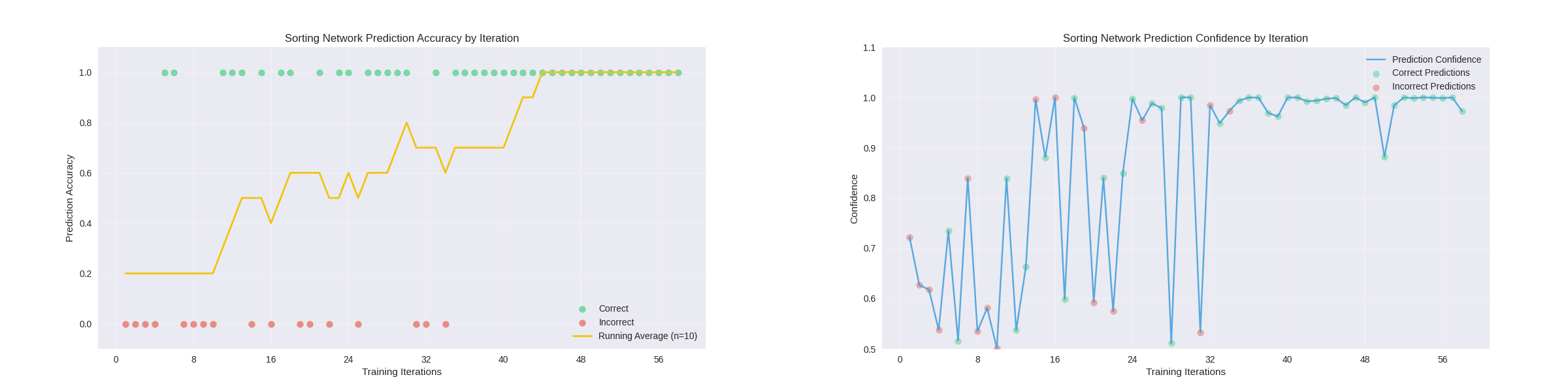
After the network was trained, it could then be redeployed and retrained using a new sorting method. below are the results from redeploying the network in the demo in video and another from an extended training session in the network_training node. For comparison, I have also provided an example of an extended training session with no pretraining, showing that a pretrained network learns faster than the untrained network, even when using a different training method.
Extended Training with Pretraining:
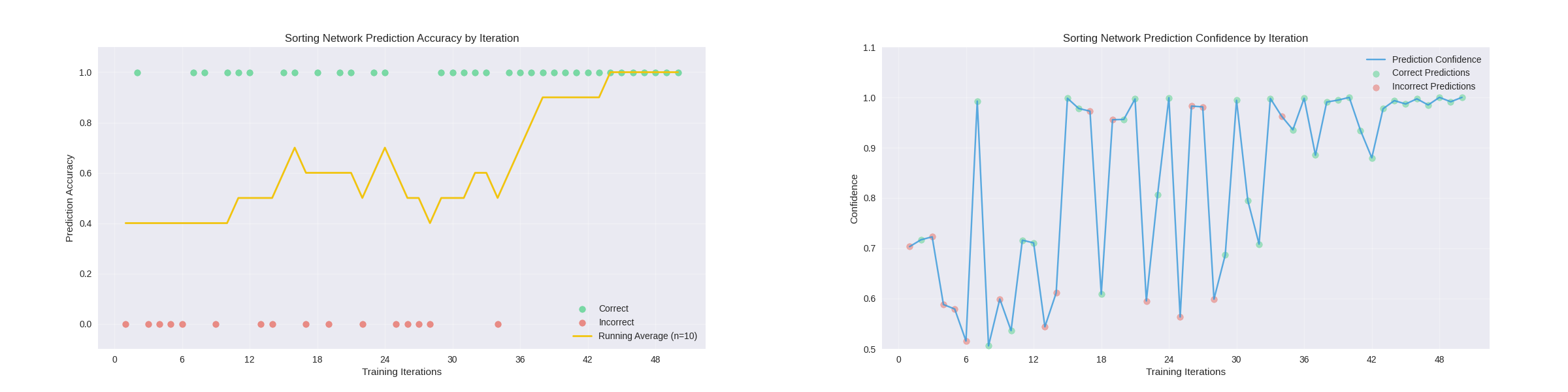
Extended Training without Pretraining:
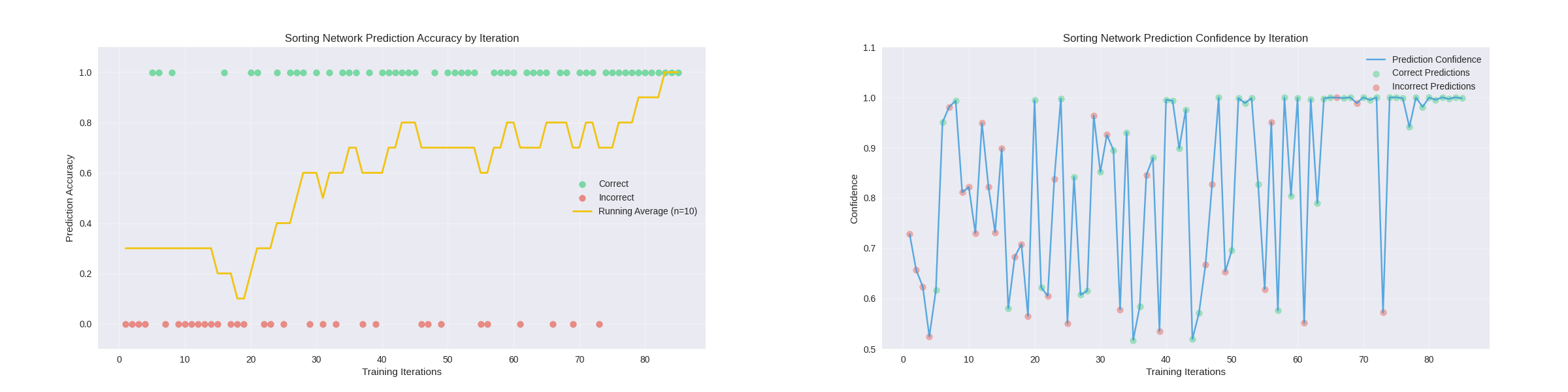
Finally, the network can be deployed again to learn aother new training method.
Demo with Pretraining:
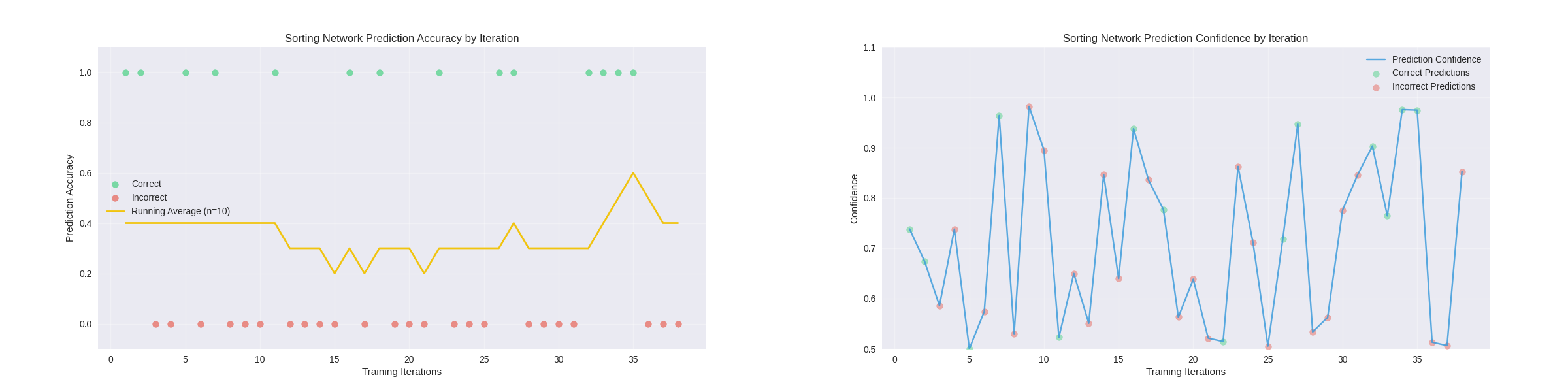
Extended Training with Pretraining:
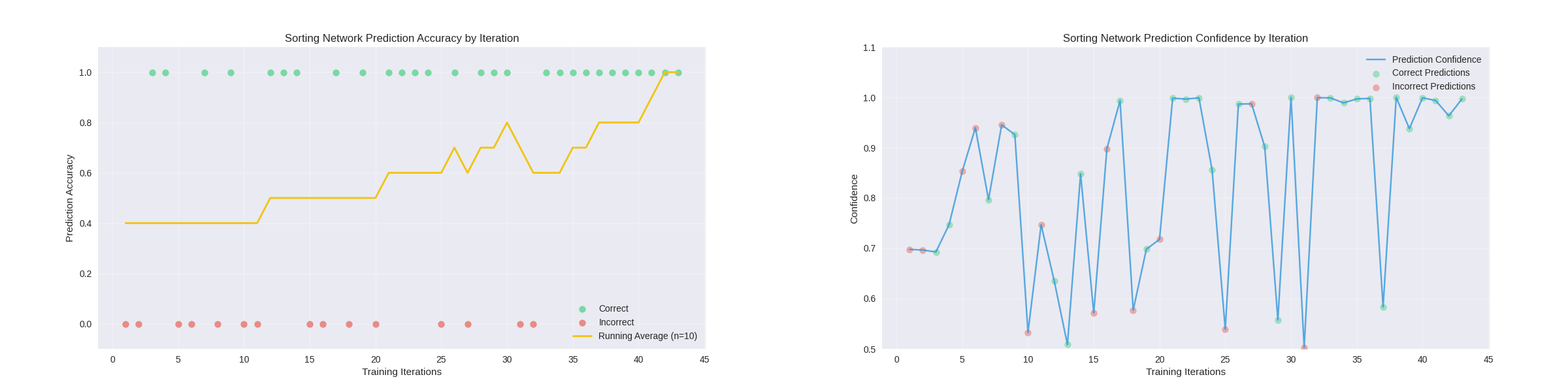
Extended Training without Pretraining:
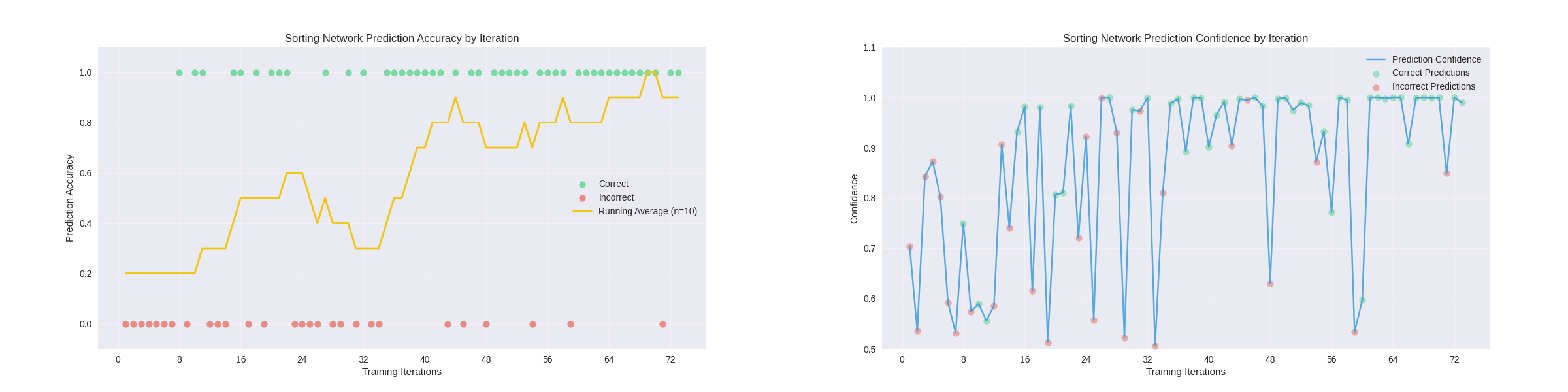
Conclusion and Future Work
This project successfully integrated robotics, computer vision, and machine learning to create an adaptive block sorting system. This system features a unique approach to training neural networks online via feedback and interaction with a human operator, as well as interaction between the different networks. The system’s ability to learn and adapt to new sorting criteria, demonstrates potential for intelligent automation in industrial settings. Future work on this project could include:
- Extending the system to handle a wider variety of objects with more complex shapes and materials, perhaps using an object detection model or vision-language-action model.
- Implementing more advanced reinforcement learning algorithms to further improve adaptability and efficiency.
- Improve gesture sorting network to categorize even more gestures and make models more robust between different users.
By combining adaptive learning with precise robotic control, this project lays the groundwork for more intelligent automation systems. The potential applications span various industries, from manufacturing and logistics to healthcare and beyond.
Acknowledgements
Thanks you to Matt Elwin and to Yayun Du for their guidance and support with this project!