Quadruped Walking with Reinforcement Learning
Overview
In this project, I applied reinforcement learning to teach a simulated ant to walk in the Gym Ant environment, focusing on the Soft Actor-Critic (SAC) algorithm. SAC, an off-policy method excelling in continuous action spaces, uses a maximum entropy framework to balance exploration and exploitation. I aimed to achieve both quick learning and high performance in the ant’s walking behavior. The project involved fine-tuning algorithm aspects and customizing the reward function. Testing on both the Inverted Double Pendulum and Ant environments showed successful outcomes, with notable improvements in the ant’s walking smoothness using a tailored reward function. This work demonstrates the effectiveness of modern reinforcement learning in tackling complex robotic control problems and highlights the importance of careful algorithm selection and reward function design in achieving desired behaviors.
Demo Video
Technical Approach
- Algorithm: Utilization of the Soft Actor-Critic, a model-free, off-policy algorithm that operates on the principles of maximizing entropy for robust learning.
- Environment Setup: Configurations included defining intricate state and action spaces, tuning parameters for optimal performance, and managing the replay buffer for experience replay.
- Network Design:
- Policy Network (Actor): Comprises three hidden layers with 128 neurons each, leading to outputs for action mean and log standard deviation, essential for the stochastic policy behavior in SAC.
- Critic Network (Q-Network): Integral for estimating the Q-values necessary for the critic aspect of SAC, using a multi-layer design to process state-action pairs.
- Hyper-Parameters: The following hyper-parameters were used in this model. These were largely based on the parameters used in the original SAC paper
- Number of episodes: 1000 (for double pendulum), 9999 (for quadruped)
- Batch size: 256
- Discount factor (gamma): 0.99
- Target smoothing coefficient (tau): 0.005
- Entropy coefficient (alpha): 0.2
- Learning rate: 3e-4 (for all optimizers)
- Replay buffer size: 1,000,000
- Hidden layer size: 128 (for both policy and Q-networks)
- Number of hidden layers: 3 (for both policy and Q-networks)
- Action space: Continuous
- State space: Continuous
- Optimizer: Adam
- Activation function: ReLU
- Environment: Ant-v4 (with custom parameters)
- Use of contact forces: True
- Contact cost weight: 0.2
- Healthy z-range: (0.3, 1.0)
- Maximum episode steps: 1000 (default for Ant-v4)
- Inference frequency: 5.0 Hz
- Servo frequency: 10.0 Hz
Soft Actor Critic Model: Soft Actor-Critic (SAC) is a robust reinforcement learning algorithm for continuous action spaces. It blends actor-critic methods with entropy maximization, using an actor to learn a flexible policy and a critic to estimate value. SAC shines in complex environments, offering good sample efficiency and stable training. It’s great at finding diverse solutions and avoiding getting stuck in suboptimal strategies. On the flip side, SAC can be computationally heavy and needs careful tuning.
Results and Observations
- Training Efficiency: The SAC demonstrated rapid learning capabilities, significantly improving the agent’s performance in navigating the complex Ant environment.
- Algorithmic Insights: The project underscored the importance of parameter tuning and algorithmic adjustments to address specific challenges such as the exploration-exploitation trade-off and policy stability.
- Final Reward: The agent achieved a final reward of 5660.59 after 9999 episodes of training, indicating successful learning of the walking task.
Training Progress Graphs:
These graphs show the training progress for the inverted pendulum and ant:
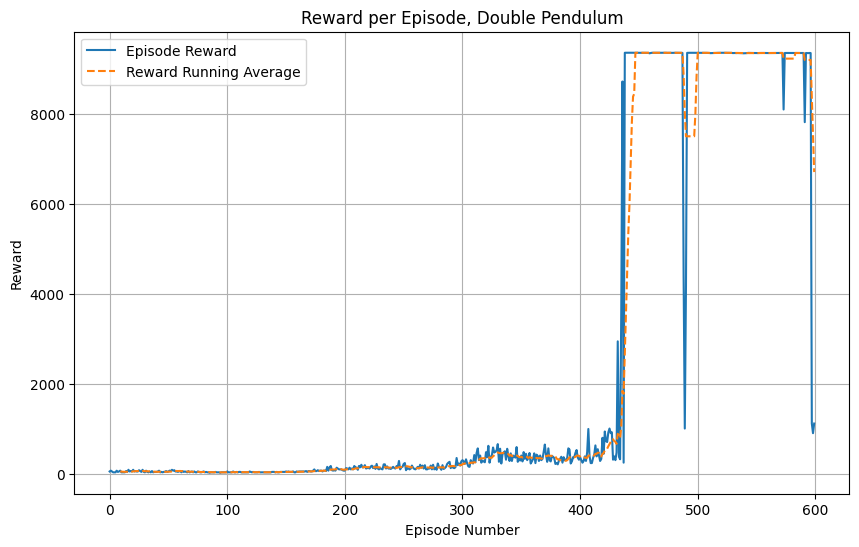
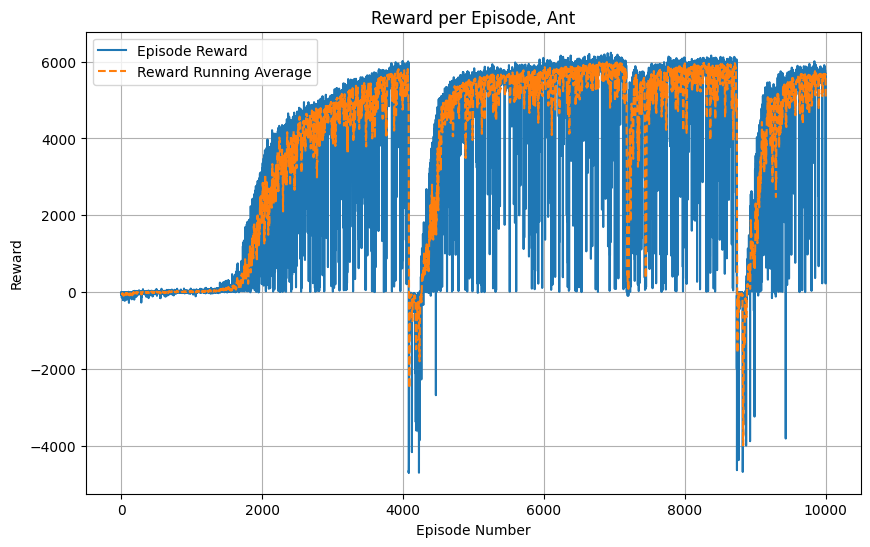
Key Observations:
- Double Pendulum Environment:
- Performance remains low and stable for the first 400 episodes.
- A dramatic jump in performance occurs around episode 400.
- After the jump, rewards quickly rise to about 9000.
- High performance is mostly maintained after this jump, with occasional sharp drops.
- The running average closely tracks the episode reward due to the sudden improvement.
- Ant Environment:
- Initial learning is slow, with a sudden improvement around episode 2000.
- Performance plateaus around 6000 reward for extended periods.
- There are two major drops in performance around episodes 4000 and 8000.
- The agent recovers quickly from these drops, suggesting robust learning as well as policy exploration.
- Episode rewards (blue line) show high variability throughout training.
- The running average (orange line) smooths these fluctuations, revealing overall trends.
- Comparison:
- Ant shows a more complex learning pattern with multiple phases, while Double Pendulum has a single, dramatic breakthrough.
- Both environments reach similar peak rewards (around 6000-9000), but through very different trajectories.
- Double Pendulum learns more abruptly, while Ant shows gradual improvement punctuated by sudden changes.
- Ant training appears more unstable overall, with frequent fluctuations and major drops in performance.
These results demonstrate the effectiveness of the SAC algorithm in tackling the complex task of quadruped locomotion, showcasing both rapid learning and high final performance.
Conclusions and Future Work
The project not only showcased the SAC’s potential in a complex simulation but also highlighted the critical aspects of implementing advanced reinforcement algorithms in environments with large state and action spaces. It sets the stage for further explorations into more sophisticated environments and more complex tasks in reinforcement learning.
Future directions include scaling the implementation to other challenging environments, exploring the impacts of different hyperparameters on learning efficiency, and integrating multi-agent dynamics for broader applicability.